


Small Language Models (SLMs) When and How to Use Them

A webinar on “Small Language Models: When and How to Use Them” was hosted by RACE (REVA ACADEMY FOR CORPORATE EXCELLENCE), REVA University to explore the benefits, limitations, and practical applications of small language models in various industries. Below is a summary of the webinar. Do check the recorded webinar here on our YouTube Channel.
Introduction
In today’s tech landscape, large language models (LLMs) like ChatGPT and Gemini are widely used, either through web interfaces or APIs. However, not everything big is necessarily better, and small language models (SLMs) offer unique advantages.
Generative AI, a subset of AI, focuses on creating content such as images, text, audio, and video. Unlike conventional AI, which makes predictions and aids in decision-making, generative AI generates new, unique content. This process is akin to dreaming, where the human brain creates new scenarios from existing knowledge. Check Figure 1 for the differentiating features of conventional AI and Generative AI.
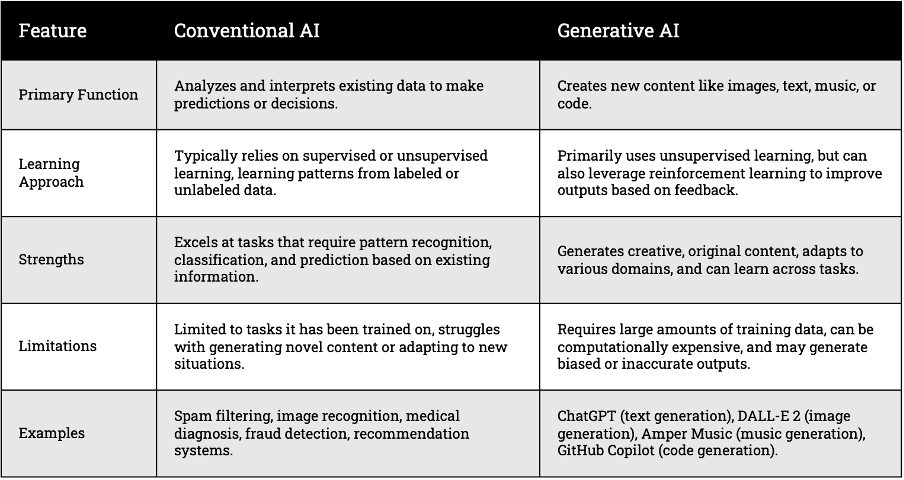
Figure 1: Difference between Conventional and Generative AI
Generative AI models are trained on vast datasets using techniques like fill-in-the-blanks, allowing them to predict and generate coherent sequences of text. While generative AI is powerful and creative, it comes with challenges like computational demands, potential biases, and hallucinations—producing information that may not be accurate. Check this link here for “The Rise and Rise of A.I. Large Language Models”.
The development of LLMs has seen exponential growth in model parameters, following a trend similar to Moore’s Law in semiconductors. This rapid advancement has spurred innovation, with numerous tech companies and startups focusing on creating increasingly sophisticated models. Despite their prowess, the evolution of language models continues, pushing the boundaries of what’s possible.
Language models (LMs) are characterized by the number of parameters they train on, which represent the intelligence and capacity of the model. Parameters are learnable weights and biases in the model’s interconnected layers, determining its performance. Larger models with more parameters generally exhibit higher intelligence and complexity.
Training large language models (LLMs) involves processing vast amounts of internet data, including sources like Wikipedia, news websites, and blogs. This process captures a wide range of information, encompassing both accurate data and biased or false information. Despite efforts to curate data and set guardrails, models can still exhibit biases, such as gender or racial biases, as seen in certain examples.
The versatility of LLMs allows them to be customized for various tasks. For instance, models trained on text excel in question answering and sentiment analysis, while those trained on images perform well in image captioning and object recognition. Speech-trained models are proficient in tasks like speech recognition and translation.
Training LLMs (Figure 2) is a resource-intensive process, requiring significant computational power, data storage, and financial investment. This makes it challenging for individuals or small entities to develop their own LLMs.
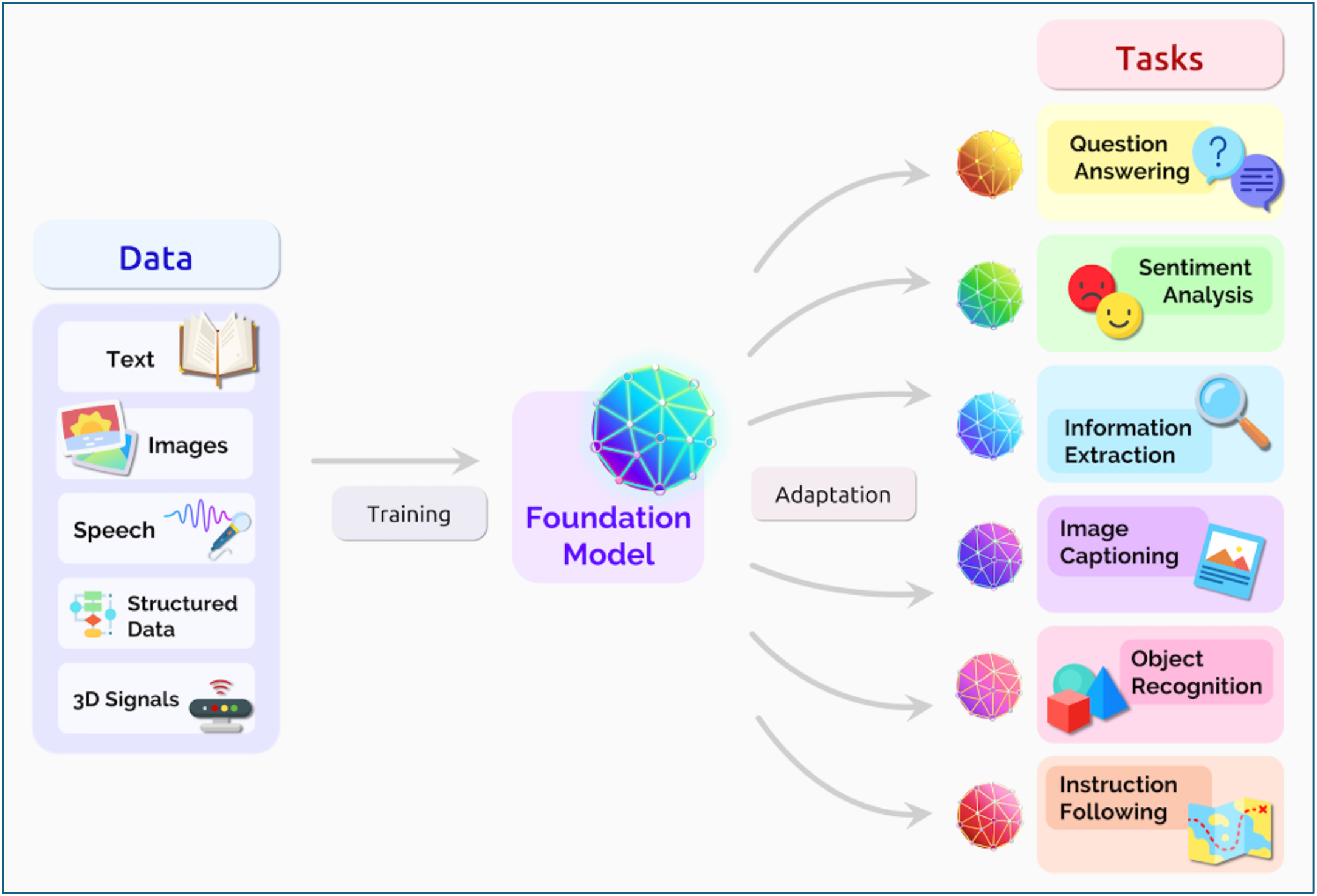
Figure 2: Training LLMs
Small Language Models (SLMs) offer a practical alternative to Large Language Models (LLMs) by providing efficient, offline capabilities. For instance, an SLM app can assist farmers with crop advice without requiring internet connectivity, unlike traditional assistants like Siri or Google Assistant. SLMs are typically more secure, as they are trained on curated datasets rather than vast, potentially problematic data sources. They also have lower computational requirements, smaller model sizes, reduced power consumption, and a smaller carbon footprint.
SLMs are ideal for specific tasks and domains, with lower training and deployment costs compared to LLMs. They are well-suited for devices with limited resources and can operate offline, making them versatile for remote areas. Examples of SLMs (Figure 3) include models with fewer parameters, such as DistilBERT, which is smaller and more resource-efficient.

Figure 3: Examples of SLMs
In contrast, LLMs, with their massive parameter counts (e.g., 100 billion parameters), offer broader versatility but come with higher resource demands and costs. SLMs, with fewer parameters, are more manageable and practical for specific use cases, especially in constrained environments. Check Figure 4 for differences in SLMs and LLMs.
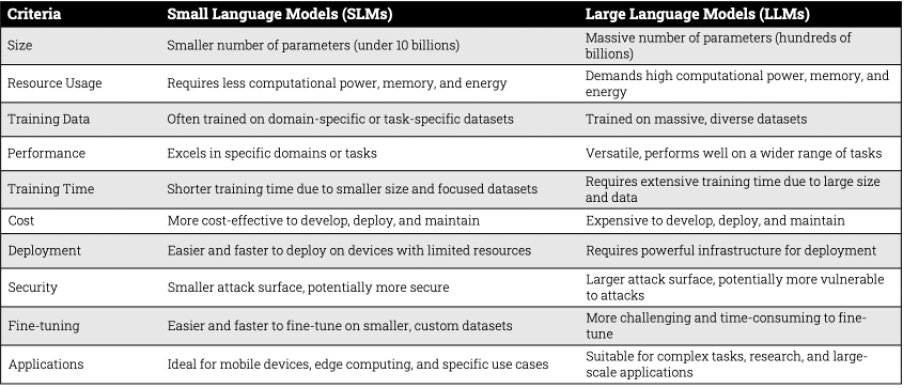
Figure 4: Difference Between LLMs and SLMs
Practical Demonstration of Offline SLM using Ollama
For a practical demonstration, attendees were guided through downloading and installing an SLM using Ollama. After installation, users ran commands to download and execute a model, which can operate offline. The demonstration showed how to interact with the model, set prompts, and perform tasks such as answering questions in different styles. This approach highlights the benefits of using SLMs for applications where internet access is limited or where data privacy is a concern. The session also touched on the potential for customizing models and using them in various scenarios, including offline environments.
The session ended with Q&A.
Conclusion
SLMs represent a significant leap forward in technological innovation. By combining the creative power of AI with the customisation of SLMs, we can unlock new possibilities and efficiencies in various fields. Understanding the capabilities of SLMs and applying them thoughtfully to real-world problems is key to harnessing this technology. Whether you are a novice or an expert in AI, the time to explore SLMs now.
Check out here to learn more about our bespoke program on MTech in Artificial Intelligence which combines, AI/ML Technologies, Generative AI, and Global certifications with Azure and AWS.
Visit our website race. reva.edu.in or Call: +91 80693 78092 or write to us: enquiry@race.reva.edu.in.
We look forward to seeing you at our next event!
