


Improving Language Understanding with Vokenization

This blog covers:
- Background to Vokenization
- What is the need for Vokenization in NLP?
- About Vokenization
- Step-by-step procedure to do Vokenization
- Summary of Vokenization
- Model Testing and Challenges in Vokenization.
Background
Let’s begin by asking a fundamental question. How does a child learn any language? Typically, a child learns language by listening, speaking, writing, reading, and, via interaction in the real world. In other words, human beings learn language through multi-modal interactions. Language learning can never be a unimodal arrangement! Applying the same principles to machines can yield very powerful and rich results. Imagine training a machine not just using language but also visual images to supplement language. This is where the idea of vokenization comes in.
Vokens are token-related images. In simple language, Vokens have visualised tokens.
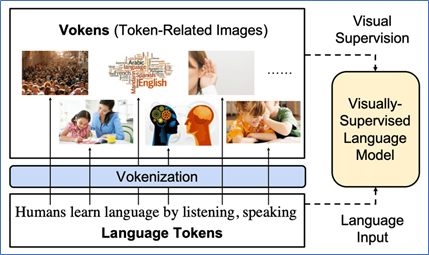
Figure 1: Importance of Vokenization (Extracted from the article here)
Image captions mostly require grounded language. However, grounded language has a large discrepancy with other kinds of natural languages. Existing language pre-training frameworks are driven by contextual learning which only considers the language context as self-supervision.
To resolve the above challenge, data scientists and a research team from UNC-Chapel Hill introduced a novel technique that gets the context of the image right.
Need for Vokenization
Since humans learn in a multi-layered, multidimensional way, why should machines be an exception? This is the motivation behind the new approach to learning called vokenization which extrapolates language-only data by contextually mapping language “tokens” or the words used to train language models, to related images, or “vokens”.
Existing methods like BERT and GPT do not consider grounding information from the external visual world. A language model trained on only pure text data many times gives poor results. Hence a language model trained on a visually supervised language model gives significantly better results as compared to a model trained on pure text.
Models like GPT-3 are trained on syntax and grammar, not creativity or common sense. The researchers at the University of North Carolina–Chapel Hill attempted to combine language models with computer vision. For example, auto-generated image captions often cannot infer context. Vokenization would enable machines not just to recognize objects but to really “see” what is in them.
Computer Vision and NLP
What is a better way to make a model learn languages?
Vokenization is a process which allows us to generate large visually grounded language data. The authors state that there is a huge divide between the visually grounded language datasets and pure-language corpora. Hence, they developed a technique named “Vokenization” that extrapolates multimodal alignments to language-only data by contextual mapping language tokens to their related images. Using the vokens as the input data the authors suggest a new pre-training task for language: voken classification. The “vokenizer” is trained on relatively small image captioning datasets and then applied to generate vokens for large language corpora.
Step-by-step procedure to do Vokenization
Below is a four-step process to do vokenization.
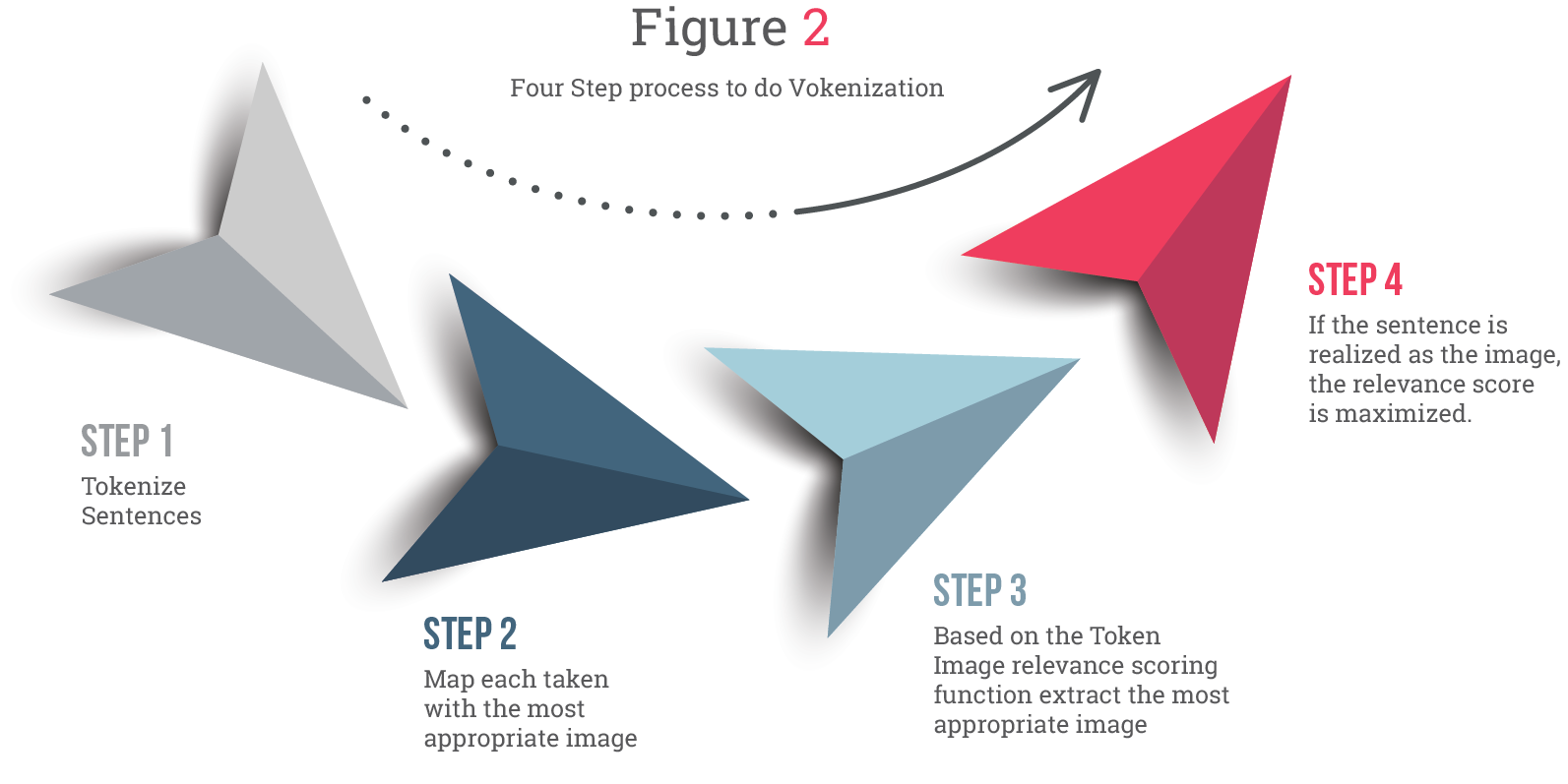
Figure 2: Four Step process to do Vokenization (adapted from the blog here)
Summary of Vokenization
The model takes in both a sentence (composed of tokens) and an image as an input and assigns each token in the sentence to its corresponding relevant image. The sentence becomes a sequence of tokens in the vokenizer, and this outputs a relevance score for the tokens and images within the context of the sentence as shown in Figure 3.
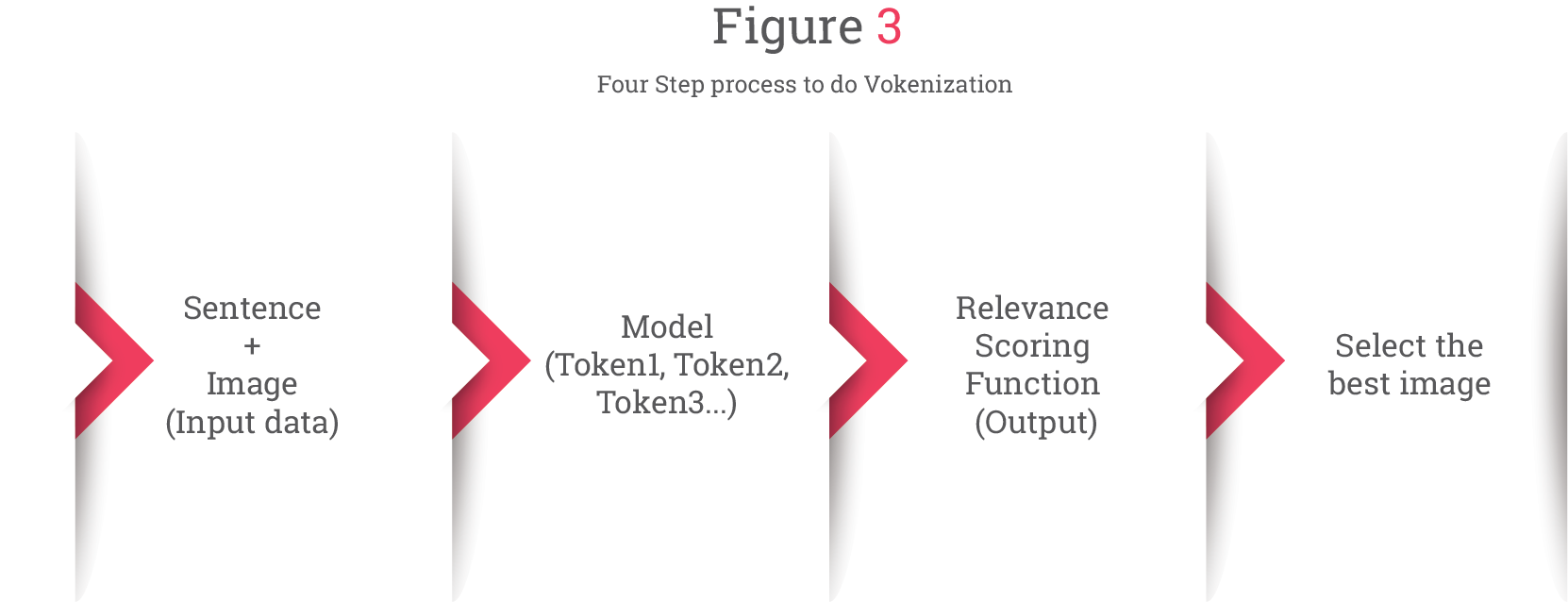
Figure 3: Four Step process to do Vokenization (adapted from the blog here)
Note: Relevance score is estimated between the token and image while considering the whole sentence as a context.
Model Testing and Challenges
The testing of the Vokenizer model was done by the authors on English Wikipedia and its subset Wiki 103. The Vokenizer is used to generate vokens for these two datasets. The pre-trained models are then fine-tuned on GLUE and others. The results appear to be satisfactory. When the unique related image is hard to define, the vokenizer aims to ground the non-concrete tokens to relevant images. This strategy helps understand the language and leads to improvement. There could be misalignments because of sentence-image weak supervision in the training data since the strong token-image annotations are not available.
MIT researchers believe that Vokenization is going to be the next breakthrough in AI with Common Sense with many applications in Robotics and AI and vision and text systems.
