


Recommendation Systems

Introduction
Has it ever made you curious how Netflix recommends movies or how Amazon Prime recommends new series? All this is made possible by implementing a recommendation system. From E-commerce apps to On-demand streaming platforms, recommendation systems aid us in discovering new movies, products, music, and the list is endless. In this blog, we will dive into the intriguing world of Movie Recommendation Systems and explore the Collaborative filtering algorithms.
Understanding Recommendation Systems
How difficult does it seem to choose a movie these days? A new era of information, the big data era, has begun because of the current technology’s rapid increase in data generation. However, the abundance of data has created the issue of information overload. It might be interpreted as a feeling of being overloaded because of the vast amount of information that must be processed and decided upon by the average person. “There are more than 700 movies released each year in North America alone. If you think that’s a lot, compare it to 1,500 – 2,000 movies released in India each year.” Source – Movie Statistics
On the plus side, the same data can be a benefit and help develop effective recommendation systems. A type of information filtering technology known as a recommender system makes movie recommendations to the user based on the aspects they find most appealing. A strong recommendation engine boosts the effectiveness of search, essentially forecasts user preferences and interests, and offers films that are more pertinent to the user.
One of the key benefits of recommendation systems is personalization.
Users that use personalisation find new products that suit their likes and spend less time and effort looking for relevant material. Through the application of machine learning and data analysis techniques, these systems also assist in reducing information overload and increasing user engagement and happiness.
Recommendation System -Approaches
Machine learning techniques for recommender systems fall into two categories: collaborative filtering and content-based filtering. These two filtering techniques are combined in modern recommendation systems.
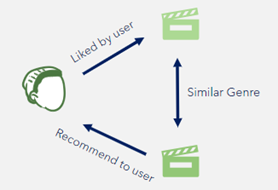 Figure 01: Content-Based Filtering
Figure 01: Content-Based Filtering
a. Content-Based Filtering
Recommendations are given by content-based systems depending on the user’s prior consumption patterns. The system might, for instance, suggest films that are similar to a user’s earlier picks in terms of genre, performers, and directors. The more activities a user does, the more accurate the system may become. The main disadvantage of using such a basic recommendation system is that users are not exposed to a wide variety of films. If a user doesn’t watch a variety of films, their pleasure may suffer, which could have a negative impact on the business.
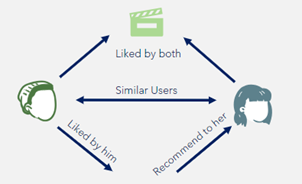 Figure 02: Collaborative Filtering
Figure 02: Collaborative Filtering
b. Collaborative Filtering
The most well-known algorithm in recommender systems is the collaborative-filtering recommendation. It sorts by comparing user and movie similarities. It examines the user characteristics as well as the features of the previous films that users have seen or looked up.
Collective methods calculate the degree of user similarity. Finding a group of people whose preferences, likes, and dislikes are like those of user X is the first step in this computation. The neighborhood of X refers to this collection of “similar” people. User X is then given recommendations for films based on which people in the area enjoy the most. The precision of the algorithm in locating the target user’s neighborhoods may boost efficiency.
However, the cold-start issue (every time a new user or movie is brought to the system, there is no data accessible on it) and data privacy issues affect collaborative screening.
Collaborative filtering is further divided into two types: memory-based approaches and model-based approaches.
Memory-based collaborative filtering
This method calculates how similar users or objects are using past user ratings data. The idea is to establish a correlation of similarity between users or items and identify the most similar to suggest undiscovered items.
This filtering is again separated into two categories: user-based collaborative filtering and item-based collaborative filtering.
User-based collaborative-filtering
The premise behind user-based collaborative filtering is that viewers would gravitate towards films that other users who share their tastes also enjoy. As a result, folks who like the same films are grouped together.
Step 1: Is to create a matrix of user-item ratings for the films that viewers have rated, liked, or searched for.
Step 2: Calculate the similarity score between users, which aids in determining user correlations.
Step 3: Based on correlation, make recommendations that are supported by higher correlations.
Initial similarity preferences in this situation fail as the user’s preferences alter. Another weakness of this strategy is shilling assaults (fake user profiles that present biased preferences).
Item-based collaborative-filtering
The foundation of item-based collaborative filtering is the assumption that viewers will enjoy films that are comparable to those that the user has previously enjoyed.
Step 1: Create a User-User Item matrix by identifying films that are comparable to those that the viewer has rated, loved, or searched for in the past.
Step 2: Calculate movie similarity scores.
Step 3: Based on correlation, make recommendations that are supported by higher correlations.
The key benefit is that unlike viewer preferences, which can change, films do not, and this approach has less of an impact on Shilling attacks.
Model-based collaborative filtering
To create systems that attempt to predict user ratings for unrated objects, this method combines machine learning and data mining methods. These extract features from the dataset to build the model rather than using the entire dataset to produce suggestions. As a result, it is known as model-based filtering.
Model-based collaborative filtering methods are widely used. The most popular models include latent Dirichlet allocation, Markov decision process-based models, and matrix factorization models using an SVD to reconstruct the rating matrix.
Conclusion
In conclusion, the field of commercial recommendation systems often relies on the combination of content-based filtering, collaborative filtering, and demographic-based methods, resulting in an enriched hybrid model that harnesses the strengths of each approach. Nevertheless, the success of such systems depends on meticulous consideration of the chosen approaches and models, while simultaneously tackling prominent hurdles like data sparsity and the cold start problem. To validate the efficiency of a proposed model, comprehensive assessments of accuracy, quality, and scalability must be conducted across different datasets. These evaluations affirm the potential of our hybrid recommendation system, paving the way for more effective and personalized recommendations in real-world streaming applications.
